<label id="xw3od"><meter id="xw3od"><bdo id="xw3od"></bdo></meter></label>
<label id="xw3od"><meter id="xw3od"></meter></label>
<bdo id="swiqe"></bdo>
<button id="swiqe"><input id="swiqe"></input></button>
<li id="swiqe"><source id="swiqe"></source></li>
<center id="swiqe"></center>
<li id="swiqe"></li>
<abbr id="swiqe"></abbr>
加入收藏
免費注冊
用戶登陸
首頁
展示
供求
職場
技術
智造
職業
活動
視點
品牌
鐠社區
今天是:2025年7月7日 星期一 您現在位于:
首頁
→
產通視點
→ 創新科技(人工智能)
美國AI超算公司Cerebras推出WSE-3人工智能芯片
2024年3月15日
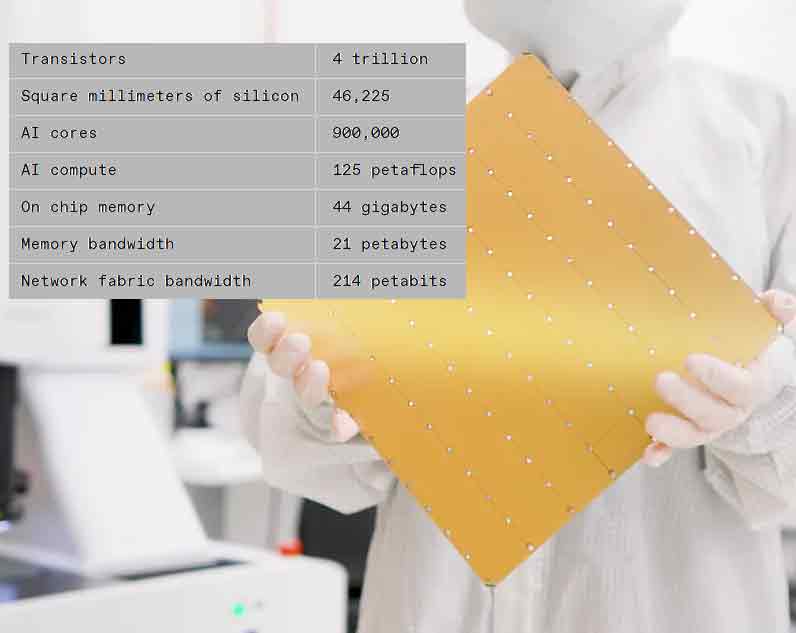
【產通社,3月15日訊】美國AI超級計算機公司Cerebras表示,其下一代waferscale AI芯片的性能比上一代產品提高一倍,而消耗相同的功率。晶圓級引擎3(WSE-3)包含4萬億個晶體管,由于使用了更新的芯片制造技術,比上一代產品增加了50%以上。該公司表示,將在新一代AI計算機中使用WSE-3,這些計算機目前安裝在達拉斯的一個數據中心,形成一臺能夠進行8億次浮點運算的超級計算機。
該公司表示,CS-3可以訓練多達24萬億個參數的神經網絡模型,是當今最大LLMs的10倍以上。公司已經與高通達成了一項聯合開發協議,旨在將AI推理的性價比提高10倍。
有了WSE-3,Cerebras可以繼續生產世界上最大的單芯片。該芯片呈正方形,邊長215毫米,使用了幾乎整個300毫米的硅晶圓來制造一個芯片。芯片制造設備通常僅限于生產不超過約800平方毫米的硅片。芯片制造商已經開始通過使用3D集成和其他先進封裝技術來組合多個芯片,從而擺脫這一限制。但即使在這些系統中,晶體管數量也有數百億個。
像往常一樣,如此大的芯片伴隨著一些令人興奮的最高級。
你可以在WSE芯片的繼承中看到摩爾定律的影響。第一個于2019年首次亮相,使用臺積電的16納米技術制造。對于2021年抵達的WSE-2,Cerebras轉向了臺積電的7納米工藝。WSE-3是用這家晶圓巨頭的5納米技術制造的。
自第一個超大規模芯片問世以來,晶體管數量增加了兩倍多。同時,用途也發生了變化。例如,芯片上AI核心的數量明顯持平,內存和內部帶寬也是如此。盡管如此,每秒浮點運算次數的性能提升超過了所有其他指標。
圍繞新AI芯片CS-3構建的計算機旨在訓練新一代巨型大型語言模型,比OpenAI的GPT-4和谷歌的Gemini大10倍。該公司表示,CS-3可以訓練多達24萬億個參數的神經網絡模型,是當今最大LLMs的10倍以上,而無需其他計算機所需的一套軟件技巧。根據Cerebras的說法,這意味著在CS-3上訓練一個1萬億參數模型所需的軟件與在GPU上訓練一個10億參數模型一樣簡單。
可以組合多達2048個系統,這種配置將在一天內從頭開始訓練流行的LLM Llama 70B。不過,該公司表示,目前還沒有那么大的項目。
Cerebras CEO Andrew Feldman表示,神經網絡模型的執行是AI應用的天花板。Cerebras估計,如果地球上每個人都使用ChatGPT,每年將花費1萬億美元——更不用說大量的化石燃料能源了。
Cerebras和高通建立了合作伙伴關系,目標是將推理成本降低10倍。他們的解決方案將涉及應用神經網絡技術,如權重數據壓縮和稀疏性——刪除不必要的連接。這樣,經過大腦訓練的網絡將在高通的新推理芯片AI 100 Ultra上高效運行。(來源:IEEE;編譯:鐠元素)
→
『關閉窗口』
365pr_net
[
→ 我要發表
]
上篇文章:
印度政府投資152億美元推動半導體芯片制造業
下篇文章:
全球半導體芯片銷售額2024年1月份高位回落2.1%
→
評論內容
(點擊查看)
(沒有相關評論)
您是否還沒有
注冊
或還沒有
登陸
本站?!
分類瀏覽
|
創新科技
>|
人工智能
信息科學
通信技術
光電子學
材料科技
能源科技
先進制造
半導體技術
|
行業觀察
>|
行業動態
市場分析
|
家庭電子
>|
市場觀察
廠商動態
技術趨勢
|
移動電子
>|
市場觀察
廠商動態
技術趨勢
|
辦公電子
>|
市場觀察
廠商動態
技術趨勢
|
汽車電子
>|
市場觀察
廠商動態
技術趨勢
|
通信網絡
>|
市場觀察
廠商動態
技術趨勢
|
工業電子
>|
市場觀察
廠商動態
技術趨勢
|
安全電子
>|
市場觀察
廠商動態
技術趨勢
|
工業材料
>|
市場觀察
廠商動態
技術趨勢
|
固態照明
>|
市場觀察
廠商動態
技術趨勢
|
智能電網
>|
市場觀察
廠商動態
技術趨勢
關于我們
┋
免責聲明
┋
產品與服務
┋
聯系我們
┋
About 365PR
┋
Join 365PR
Copyright @ 2005-2008 365pr.net Ltd. All Rights Reserved. 深圳市產通互聯網有限公司 版權所有
E-mail:postmaster@365pr.net
不良信息舉報
備案號:
粵ICP備06070889號
主站蜘蛛池模板:
亚洲精品无码久久久久APP
|
久久精品国产精品亚洲毛片
|
亚洲精品第一国产综合亚AV
|
国产免费看JIZZ视频
|
亚洲人成网站18禁止久久影院
|
ww在线观视频免费观看
|
亚洲毛片免费观看
|
久久福利资源网站免费看
|
亚洲欧洲综合在线
|
成人A级毛片免费观看AV网站
|
亚洲国产品综合人成综合网站
|
一级女人18毛片免费
|
亚洲三级高清免费
|
亚洲精品国产精品乱码不99
|
黄桃AV无码免费一区二区三区
|
亚洲色无码一区二区三区
|
国产99在线|亚洲
|
成人激情免费视频
|
67pao强力打造67194在线午夜亚洲
|
2015日韩永久免费视频播放
|
久久国产成人亚洲精品影院
|
www.亚洲精品
|
久久99精品免费一区二区
|
亚洲av午夜福利精品一区
|
永久免费无码日韩视频
|
www视频在线观看免费
|
亚洲欧美中文日韩视频
|
亚洲国产成人久久综合野外
|
日韩精品无码免费一区二区三区
|
亚洲fuli在线观看
|
免费大黄网站在线观看
|
日韩精品在线免费观看
|
日韩精品亚洲aⅴ在线影院
|
国产精成人品日日拍夜夜免费
|
亚洲人成激情在线播放
|
亚洲 另类 无码 在线
|
日韩人妻一区二区三区免费
|
亚洲AV性色在线观看
|
久久被窝电影亚洲爽爽爽
|
99爱在线精品免费观看
|
久久国产精品免费一区
|
<abbr id="oac2k"></abbr>
<button id="oac2k"><input id="oac2k"></input></button>
<rt id="oac2k"></rt>
<tfoot id="oac2k"><delect id="oac2k"></delect></tfoot>
<strike id="oac2k"><tr id="oac2k"></tr></strike>
<sup id="oac2k"><input id="oac2k"></input></sup>
<code id="oac2k"><tr id="oac2k"></tr></code>